MunkiMagic in the Cloud - Moving our Munki Infrastructure to AWS
tl;dr This post describes my development journey toward munkimagic-in-aws, our Munki infrastructure as ‘Infrastructure as Code’. We collaboratively manage around 250 kiosk Mac Mini client machines which are distributed in 40 offices across the globe and act as ‘Zoom Rooms’.tl;dr This post describes my development journey toward munkimagic-in-aws, our Munki infrastructure as ‘Infrastructure as Code’. We collaboratively manage around 250 kiosk Mac Mini client machines which are distributed in 40 offices across the globe and act as ‘Zoom Rooms’.
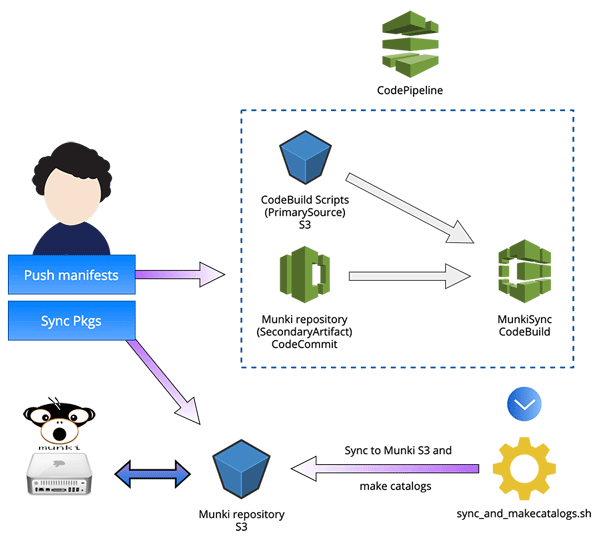
In a nutshell: /manifests and /pkgsinfo of our Munki repo are pushed to CodeCommit, which sets a CodePipeline in motion that makes a CodeBuild container sync the repo to an S3 bucket and then does makecatalogs on the bucket with @clburlison’s Munki-s3Repo-Plugin. Packages are synced to the bucket via aws s3 sync. We use @waderobson’s Munki middleware s3-auth on clients to access the Munki repo.
You can see an asciicast of how it works here.
At our company we have around 250 Mac Minis that act as Zoom meeting rooms distributed across 40 offices around the globe. We had been using Munki in combination with a GoCD pipeline that would do makecatalogs on a Mac Pro (located in a datacenter somewhere in the US) every time changes to the Munki repository had been pushed to a git repository on a private Gitlab instance. The munki repository was finally hosted in an S3 bucket that was set up as a webserver and served by CloudFront. Regional teams could add or change manifests, but not add packages, as direct access to the S3 bucket and Mac Pro was limited.
Unfortunately some time in May 2018, shortly after I had joined and learned to appreciate Munki for how it made it easy for us to provision and manage these client machines, something in our setup broke and we were unable to add or change manifests. We went back to manually setting up and patching machines, hoping that our Munki setup would soon work again.
My colleague Steve (@squirke), who set up the initial infrastructure, was entertaining the idea of completely rehauling everything and using ‘Infrastructure as Code’ for what we would from then on refer to as Munki 2.0. I was suddenly confronted with terms like serverless, AWS services like CloudFormation, projects like munki-in-a-cloud and terraform-aws-munki-repo … and my head was spinning while trying to comprehend this wall of new information. I was super intrigued by the challenges of this project and determined to learn everything I needed to contribute a bit to Munki 2.0 or at least be able to understand what’s happening.
Unfortunately Munki 2.0 could not be treated with high priority, as Steve was quite busy developing our Mobile Device Management solution. I myself could also not dedicate much time to this during work hours. But I was so engrossed by the challenge that I at some point couldn’t wait any longer and began working on this on my own in my free time. We initially played around with serverless.com, but it was a bit too abstract for me to get much out of it. I felt more drawn to defining the resources in yaml and deploy a CFN stack via aws-cli. IaC, AWS and Munki were all new concepts and technologies for me, but after spending an enormous amount of time reading AWS docs and searching github for CloudFormation examples that sort of went in the direction of what we wanted to do, i started to get an idea of what needed to be done. I also was super fortunate to work with so many talented and experienced people that gave me support and guidance whenever I needed it.
OK. So, what did we want Munki 2.0 to look like?
- It should be described as
Infrastructe as Codeand therefore easy to deploy and destroy - Every member of each regional team should be able to be completely independent in maintaining their fleet of Mac Minis, being able to add, change or delete manifests, as well as import new packages into Munki
- It should be fairly easy to use, as not every member of the team is necessarily comfortable working with the CLI
/manifestsand/pkgsinfoshould be kept in version control- The munki repo should be hosted in S3, but the S3 bucket should not be configured as a webserver and instead only be accessible by clients with Wade Robson’s s3-auth middleware.
makecatalogsshould be executed directly on the S3 bucket with clburlison’sMunki-s3Repo-Plugin
First steps towards Munki 2.0
In my first iteration I manually created a CodeCommit repository and some buckets and then deployed a CFN stack that created the following resources:
- IAM users
- A lambda function
- A CodeBuild container
So, this worked. After manually setting the Lambda to trigger when pushing manifests to CodeCommit, the CodeBuild container would run a shell script that pulls the git repo, syncs it to S3 and executes makecatalogs on the S3 bucket. (Initially, we wanted the lambda to pull the repo and sync it to the bucket, but I couldn’t figure out how to install boto3 inside the lambda, pull the git repo and sync it to the S3 bucket. I think there was a limitation in regards to the size of the packages that I could load into the lambda.)

I showcased this to Ben, another colleague of mine that has a lot of experience with AWS and got a lot of useful feedback and suggestions:
- Use a CodePipeline instead of a Lambda
- Run a bootstrap script before my deploy script, to programmatically create the resource I created manually
- Be as restrictive and granular as possible in regards to permissions
What followed was a frustrating week of trying to figure out what exactly I can do with a CodePipeline and how I could use it for Munki 2.0. Also .. how do I feed the git repo to the CodeBuild container and how do I deliver the buildspec.yaml for the CodeBuild container as well as the scripts that would sync the repo to S3 and makecatalogs for the CodeBuild container? I used every opportunity I could get to speak with colleagues about this and after another week I suddenly had a working pipeline.
Now, when pushing a commit to the repo the pipeline would trigger and deliver a zipped copy of the git repo, makecatalogs and the libraries it needs, as well as sync_and_makecatalogs.sh that the CodeBuild container would execute on each run (all of those were zipped and synced to a dedicated S3 bucket during initial deployment). It was nice to see the build time of the container go way down, because I didn’t have to install git and pull the repo anymore.
Before deploying my stacks I would set a few env variables (aws_profile, region, resource names), run bootstrap.sh and then run deploy.sh (I still have an asciicast that shows the process here). Later, I merged both scripts into munkimagic.sh and added the --deploy and --destroy flags. I also spent quite some time on permissions, making sure to only give each resource no more access than it needed to fulfill its purpose.
This is what it now looks like:
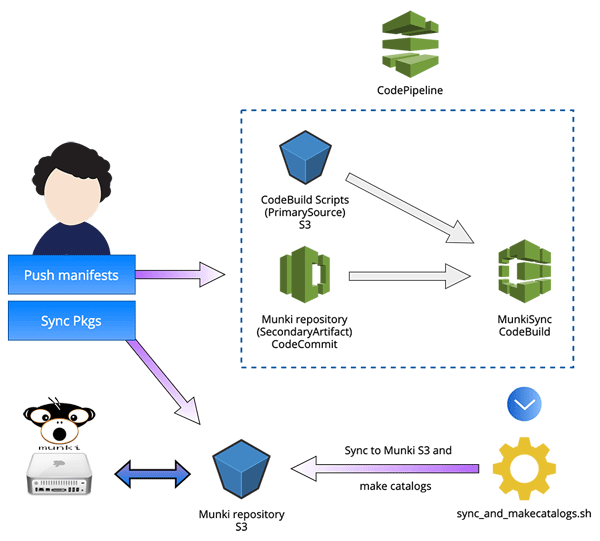
In my next catchup with Ben I showcased the changes I had made and got one final advice:
- Use
makeinstead of a shell script
I had zero experience with make and appreciated the challenge and opportunity to make use of it. Writing shell in a Makefile that creates lots of variables and writes them to and reads them from a file (munki.env) after verifying that the values are correct was quite challenging, but at some point I got used to all the @, ; \ and $$ and managed to get the results I wanted.
Makefile of munkimagic-in-aws
$ make help
> Help
make configure → Configure MunkiMagic
make deploy → Deploy MunkiMagic
make destroy → Destroy MunkiMagic
make reset → Reset configuration
- make configure = populate
munki.env - make deploy = deploy bootstrap stack, deploy munki stack
- make destroy = empty all buckets and delete stacks
- make reset =
rm munki.env
I really liked how this worked now, and how much more elegant it was to issue make deploy and make destroy instead of ./munkimagic.sh [--deploy | --destroy].
So, now that I had finished munkimagic-in-aws, the next step was to figure out how everyone on the team could manage the Mac Minis in the meeting rooms of their region. My goal was to streamline the process of updating the repo and thereby ensure a consistent and standardised workflow that made it as easy and straightforward as possible for anyone on the team to contribute to our Munki repo. I also wanted to document the technical side as well as I could, for anyone interested in how it works.
Another Makefile for the maintenance of our munki repository
Since I had just spent a good amount of time writing a Makefile for munkimagic-in-aws I liked the idea of writing another one for the Munki admins that would make changes to our Munki repo. But which steps should be taken care of by the Makefile and which ones by the Munki admins themselves?
Before being able to access and make changes to the Munki repo, a few things needed to be set up. Tools like aws-cli, boto3, munkitools needed to be installed. An SSH key pair had to be created to access the remote git repository, the local git repository needed to be set up and configured, etc.
It makes sense not to install any kind of software and instead focus on making sure every collaborator is set up in the same way. Sure, instead of having the Makefile take care of any kind of configuration for the user, I could just document how to use git to push manifests and aws-cli to sync the packages - but by having commands like make configure and make setup take over a few of the configuration steps, I could also make sure that everything is set up properly and in a unified manner for every Munki admin (e.g. everyone had user.name and user.email set in the git config of the repo) and no step in the process (e.g. sync new packages) would be forgotten.
Makefile of munkimagic-MunkiAdmin
$ make help
> Help
make configure → Configure munkimagic-MunkiAdmin
make setup → Clone Munki git repository into ↴
/current/path/munkimagic-MunkiAdmin/munkimagic-production/
make commit → Commit changes made to the munki repository
make update → Push changes to Munki bucket
make reset → Reset configuration
- make configure = populate
munkiadmin.env - make setup = configure Host in
~/.ssh/config, set up local git config of munki repository, pull repository - make commit =
git add .,git commit - make update =
aws s3 syncall packages to the s3 bucket,git pull,git pushand then monitor the pipeline and finally let the Munki admin know that the pipeline ran through and that the Munki repo in S3 is up to date. - make reset =
rm munkiadmin.env
We are currently migrating all Mac Minis from our ‘old’ Munki to Munki 2.0. I made a ‘nuke-from-orbit’-package called MunkiPhoenix.pkg, that wipes the disk by utilizing a customized version of Graham Pugh’s erase-instal.sh and installs 10.13.6 (plus additional packages, profiles and scripts), enrolls the client into Munki 2.0, runs managedsoftwareupdate and finally open ZoomPresence.app after bootstrap is completed, without any kind of user interaction necessary. We will deliver this package to clients via the broken Munki 1.0. This is still under development and I might be writing about this after it’s all done.
This was my first cloud project and I really enjoyed the journey and learnings. I want to send out a big thank you to Ben and Steve, who have been mentoring and supporting me from early on. Without their guidance I wouldn’t have managed to make munkimagic-in-aws.
Also, I’d be grateful for any kind of feedback, as I’m sure there are many things I could improve or rethink :-)